大模型的“詛咒”被DeepSeek破除了嗎?快訊
DeepSeek 的首個開源模型 DeepSeek-Coder發(fā)布,DeepSeek并非第一個使用數(shù)據(jù)蒸餾的大模型,但大模型賽道開源與否。
新一年的全球科技圈,主角儼然是DeepSeek。從發(fā)布以來,DeepSeek在整個AI產(chǎn)業(yè)鏈上引發(fā)一系列連鎖反應(yīng),無論是OpenAI,還是英偉達(dá),其明顯的震驚似乎皆驗(yàn)證著DeepSeek已奇襲成功。
而DeepSeek的初步表現(xiàn)也的確可圈可點(diǎn),數(shù)據(jù)顯示,上線5天DeepSeek日活躍用戶已超過ChatGPT,上線20天的日活達(dá)2000萬人次以上,已是ChatGPT的23%。當(dāng)前,DeepSeek成為全球增速最快的AI應(yīng)用。
在海外一眾AI玩家不可置信的同時,國內(nèi)AI領(lǐng)域一片“鑼鼓喧天”:截至目前,阿里云、百度云、騰訊云、字節(jié)火山引擎均已正式支持DeepSeek;同時,百度昆侖芯、天數(shù)智芯、摩爾線程接連宣布支持DeepSeek模型。
這也標(biāo)志著全球AI競速賽中,國產(chǎn)廠商終于又跨出了一步。而DeepSeek的出現(xiàn),是否為僵化已久的大模型行業(yè)破除了一些傳統(tǒng)“詛咒”,很多至關(guān)重要的細(xì)節(jié),其實(shí)還值得進(jìn)一步深究。
DeepSeek出圈是“偶然性”的嗎?
縱觀當(dāng)前圍繞DeepSeek的幾大主要爭議,似乎每一點(diǎn)都指向同一個問題:DeepSeek是否真的實(shí)現(xiàn)了大模型的技術(shù)突破。早在DeepSeek公布其模型訓(xùn)練成本僅為行業(yè)1/10時,就有聲音質(zhì)疑,DeepSeek是通過大幅縮減模型參數(shù)規(guī)模,或依賴母公司幻方早期囤積的廉價算力實(shí)現(xiàn)的。
從某種角度來看,這些質(zhì)疑有跡可循。
一方面,DeepSeek在縮減模型參數(shù)規(guī)模方面的“激進(jìn)”有目共睹,另外一方面,DeepSeek背后的幻方確實(shí)有一定的算力儲存。據(jù)悉,幻方是BAT之外唯一能夠儲備萬張A100芯片的公司,有報道在2023年就曾公布過國內(nèi)囤積超過1萬枚GPU的企業(yè)不超過5家。
幻方就是其中之一。
但值得一提的是,無論是模型參數(shù)規(guī)模的縮減,還是算力創(chuàng)新爭議都無法否定DeepSeek“小力出奇跡”打法的實(shí)質(zhì)意義。首先,DeepSeek-R1在參數(shù)量僅為1.5億(1.5B)的情況下,在數(shù)學(xué)基準(zhǔn)測試中以79.8%的成功率超越GPT-4等大模型。
其次,輕量化模型天然在推理能力與性能方面表現(xiàn)更出彩,訓(xùn)練和運(yùn)行成本也更低。據(jù)悉,DeepSeek以僅需1/50的價格提供了GPT-4類似的性能,在中小型企業(yè)和個人開發(fā)者中搶奪了一定的市場地位。
至于幻方對DeepSeek的加成,與其說是一場資本的偶然游戲,不如說是國產(chǎn)大模型成長的必然結(jié)果。值得注意的是,幻方量化算是國內(nèi)第一批闖入大模型賽道的企業(yè),早在2017年,幻方就宣稱要實(shí)現(xiàn)投資策略全面AI化。
2019年,幻方量化成立AI公司,其自研的深度學(xué)習(xí)訓(xùn)練平臺“螢火一號”總投資近2億元,搭載了1100塊GPU;兩年后,“螢火二號”的投入增加到10億元,搭載了約1萬張英偉達(dá)A100顯卡。
2023年11月,DeepSeek 的首個開源模型 DeepSeek-Coder發(fā)布。也就是說,這個引起海外科技巨頭集體破防的DeepSeek不是一夜之間的產(chǎn)物,而是國產(chǎn)AI廠商在大模型布局中早晚要走的一步。

不可否認(rèn),當(dāng)前國內(nèi)已具備培育“DeepSeek ”的客觀條件。公開資料顯示,一個全面的人工智能體系正在各方資本的追捧下誕生,國內(nèi)人工智能相關(guān)企業(yè)超過4500家,核心產(chǎn)業(yè)規(guī)模接近6000億元人民幣。
芯片、算法、數(shù)據(jù)、平臺、應(yīng)用……我國以大模型為代表的人工智能普及率達(dá)16.4%。
當(dāng)然,DeepSeek的技術(shù)路徑依賴風(fēng)險始終存在,這也讓DeepSeek的出圈多了一絲偶然,尤其“數(shù)據(jù)蒸餾技術(shù)”不斷遭受重重質(zhì)疑。事實(shí)上,DeepSeek并非第一個使用數(shù)據(jù)蒸餾的大模型,“過度蒸餾”甚至是當(dāng)前人工智能賽道的一大矛盾。
來自中科院、北大等多家機(jī)構(gòu)就曾指出,除了豆包、Claude、Gemini之外,大部分開/閉源LLM蒸餾程度過高。而過度依賴蒸餾可能會導(dǎo)致基礎(chǔ)研究的停滯,并降低模型之間的多樣性。上海交通大學(xué)也有教授表示,蒸餾技術(shù)無法解決數(shù)學(xué)推理中的根本性挑戰(zhàn)。
總而言之,這些都在反逼DeepSeeK乃至整個國產(chǎn)大模型賽道繼續(xù)自我驗(yàn)證,或許,國內(nèi)還會誕生第二個“DeepSeek”,從現(xiàn)實(shí)的角度來看,DeepSeek成功的必然遠(yuǎn)遠(yuǎn)大于偶然。
“開源時代”要來臨了嗎?
值得注意的是,相比于技術(shù)之爭,DeepSeek也再度引發(fā)了全球科技圈對開源、閉源的激烈論證。Meta首席科學(xué)家楊立昆還在社交平臺上表示,這不是中國在追趕美國,而是開源在追趕閉源。
談及開源模型,還要追溯到2023年Meta的一場源代碼泄露風(fēng)波。彼時,Meta順?biāo)浦郯l(fā)布了LLama 2開源可商用版本,頓時在大模型賽道掀起開源狂潮,國內(nèi)諸如悟道、百川智能、阿里云紛紛進(jìn)入開源大模型領(lǐng)域。
根據(jù)Kimi chat統(tǒng)計,2024年全年開源大模型品牌超過10個。2025年開年不足兩個月,除了大火的DeepSeeK之外,參與開源者數(shù)不勝數(shù)。
據(jù)悉,1月15日,MiniMax開源了兩個模型。一個是基礎(chǔ)語言大模型MiniMax - Text - 01,另一個是視覺多模態(tài)大模型MiniMax - VL - 01;同時,NVIDIA也開源了自己的世界模型,分別有三個型號:NVIDIA Cosmos的Nano、Super和Ultra;1月16日,阿里云通義也開源了一個數(shù)學(xué)推理過程獎勵模型,尺寸為7B。
從2023年到2025年,無數(shù)AI人才爭論不休后,大模型的“開源時代”終于要來了嗎?
可以確定的一點(diǎn)是,比起閉源模式,開源模型能在短時間內(nèi)憑借其開放性獲得大量關(guān)注。公開資料顯示,當(dāng)年在“LLama 2”發(fā)布之初,其在Hugging Face檢索模型就有超6000個結(jié)果。百川智能方面則顯示,旗下兩款開源大模型在當(dāng)年9月份的下載量就超過500萬。
事實(shí)上,DeepSeek能快速走紅與其開源模式分不開關(guān)系。2月統(tǒng)計顯示,當(dāng)前接入DeepSeek系列模型的企業(yè)不計其數(shù),云廠商、芯片廠商、應(yīng)用端企業(yè)皆來湊了把熱鬧。在AI需求鼎盛的當(dāng)前,大模型開源似乎更能促進(jìn)AI生態(tài)化。
但大模型賽道開源與否,其實(shí)還有待商榷。
Mistral AI、xAI雖然都是開源的支持者,但它們的旗艦?zāi)P湍壳岸际欠忾]的。國內(nèi)大部分廠商基本也是一手閉源,一手開源,典型的例子如阿里云、百川智能,甚至李彥宏一度是閉源模式的忠實(shí)擁躉。
原因并不難猜測。
一方面,在全球科技領(lǐng)域里開源AI公司都不受資本歡迎,反而是閉源AI企業(yè)在融資方面更有優(yōu)勢。數(shù)據(jù)統(tǒng)計顯示,從2020年以來,全球閉源 AI 領(lǐng)域初創(chuàng)公司已完成 375 億美元融資,而開源類型的 AI 公司僅獲 149 億美元融資。
這對花錢如流水的AI企業(yè)而言,其中的差距不是一星半點(diǎn)。
另外一方面,開源AI的定義在這兩年愈發(fā)復(fù)雜。2024年10月份,全球開放源代碼促進(jìn)會發(fā)布關(guān)于“開源AI定義”1.0版本,新定義顯示,AI大模型若要被視為開源有三個要點(diǎn):第一,訓(xùn)練數(shù)據(jù)透明性;第二,完整代碼;第三,模型參數(shù)。
基于這一定義,DeepSeek就被質(zhì)疑不算真正意義上的開源,只是為了迎合短期聲勢。而在全球范圍內(nèi),《Nature》的一篇報道也指出,不少科技巨頭宣稱他們的AI模型是開源的,實(shí)際上并不完全透明。
前幾日,受到“打擊”的奧爾特曼首次正面承認(rèn)OpenAI的閉源“是一個錯誤”,或許,趕著DeepSeek的熱度,一場AI界的“口水大戲”又要拉開序幕。
大規(guī)模的算力投入即將“暫停”?
這段時間,不少沉迷囤積算力的AI企業(yè)因DeepSeek的橫空出世遭到冷嘲熱諷,英偉達(dá)這類算力供應(yīng)商還在股價上跌了一個巨大的跟頭。坦白來說,DeepSeeK在某些方面的確帶來了新的突破,尤其在“壟斷詛咒”上,緩解了一部分焦慮。
但全球大模型賽道的算力需求依舊不可忽視,甚至DeepSeeK自身都未必能暫停算力投入。
需要注意的是,DeepSeek目前僅支持文字問答、讀圖、讀文檔等功能,還未涉及圖片、音頻和視頻生成領(lǐng)域。即便這樣,其服務(wù)器還困在崩潰的邊緣,而一旦想要改變形式,算力需求則會呈爆炸式增長,視頻生成類模型與語言模型之間的算力需求差距甚大。
公開數(shù)據(jù)顯示,OpenAI的Sora視頻生成大模型訓(xùn)練和推理所需要的算力需求分別達(dá)到了GPT-4的4.5倍和近400倍。從語言到視頻之間的跨度尚且如此之大,隨著各種超級算力場景的誕生,算力建設(shè)的必要性只增不減。
數(shù)據(jù)顯示,2010年至2023年間,AI算力需求翻了數(shù)十萬倍,遠(yuǎn)超摩爾定律的增長速度。進(jìn)入2025年,OpenAI發(fā)布了首個AI Agent產(chǎn)品Operator,大有要引爆超級算力場景的趨勢,這才是關(guān)系算力建設(shè)是否繼續(xù)的關(guān)鍵。
據(jù)悉,當(dāng)前大模型發(fā)展定義總共分為五個發(fā)展階段:L1 語言能力、L2 邏輯能力、L3 使用工具的能力、L4 自我學(xué)習(xí)能力、L5 探究科學(xué)規(guī)律。而Agent位于L3 使用工具能力,同時正在開啟對L4的自我學(xué)習(xí)能力的探索。
根據(jù)Gartner預(yù)測,到2028年,全球?qū)⒂?5%的日常工作決策預(yù)計將通過Agentic AI完成。如果大模型賽道按照規(guī)劃預(yù)想地一路狂奔,從L1到L5,全球各大AI企業(yè)對算力的建設(shè)更加不會忽視。
到L3階段,算力需求大概會是多少?
巴萊克銀行在2024年10月份的一則報告中預(yù)測過,到2026年,假如消費(fèi)者人工智能應(yīng)用能夠突破10億日活躍用戶,并且Agent在企業(yè)業(yè)務(wù)中有超過5%的滲透率,則需要至少142B ExaFLOPs(約150,000,000,000,000 P)的AI算力生成五千萬億個token。
即便超級應(yīng)用階段的到來還遙遙無期,在目前大模型賽道加速淘汰的激烈戰(zhàn)場上,也沒有一家企業(yè)甘愿落后一步。微軟、谷歌、亞馬遜、Meta、字節(jié)跳動、阿里、騰訊、百度……這些海內(nèi)外的AI巨頭只怕會繼續(xù)花錢賭未來。
另外,DeepSeek最為人稱道的莫過于繞開了“芯片大關(guān)”。
然而,作為算力產(chǎn)業(yè)的基石,相同投入下,優(yōu)質(zhì)的算力基礎(chǔ)設(shè)施往往會提供更高的算力效率與商業(yè)回報。《2025年算力產(chǎn)業(yè)十大趨勢》中提到過,以GPT-4為例,不同硬件配置下其性能會發(fā)生顯著差異。對比H100和GB200等不同硬件配置驅(qū)動GPT-4的性能,采用GB200 Scale-Up 64配置的盈利能力是H100 Scale-Up 8配置的6倍。
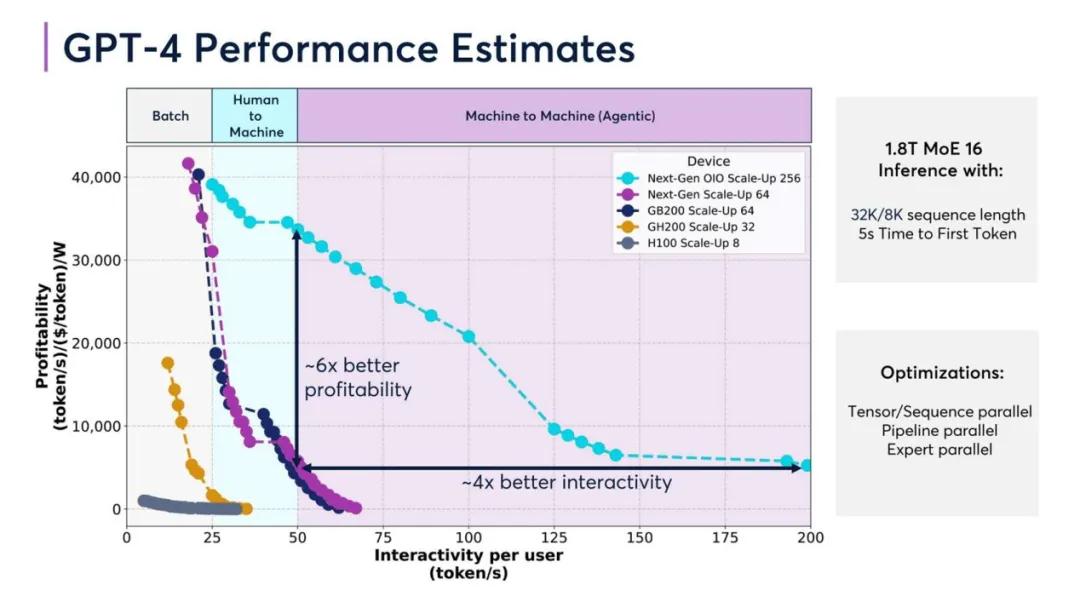
DeepSeek一問三崩的服務(wù)器,或許暗示著大模型賽道的“追芯”游戲在算力角逐環(huán)節(jié)中遲遲未能結(jié)束。據(jù)悉,2025年,英偉達(dá)下一代GPU GB300可能會出現(xiàn)多個關(guān)鍵硬件規(guī)格變化,而國內(nèi)的AI芯片國產(chǎn)化進(jìn)程也星夜兼程。
種種跡象顯示,辛苦的算力建設(shè)一時半會無法停止,反而更卷了。
1.TMT觀察網(wǎng)遵循行業(yè)規(guī)范,任何轉(zhuǎn)載的稿件都會明確標(biāo)注作者和來源;
2.TMT觀察網(wǎng)的原創(chuàng)文章,請轉(zhuǎn)載時務(wù)必注明文章作者和"來源:TMT觀察網(wǎng)",不尊重原創(chuàng)的行為TMT觀察網(wǎng)或?qū)⒆肪控?zé)任;
3.作者投稿可能會經(jīng)TMT觀察網(wǎng)編輯修改或補(bǔ)充。
