看穿你的五分鐘和下一秒:AI動作能幫助人類做到什么?互聯網+
導讀
從知道人類怎么想,到知道人類怎么做。
從知道人類怎么想,到知道人類怎么做。
相信了解電競的人,一定對“預判”二字非常熟悉。在游戲中,玩家通過豐富的對戰經驗,對對手的下一步動作進行預估并提前進行反應。在籃球、足球、格斗、拳擊等等活動中也是一樣,對于高手來說,對手腰側一動就知道對方要打出左勾拳,便可以提前做出格擋動作。
當然這種能力并不是誰都能擁有,通常都是“高手限定”。只有累積下大量經驗加上強大的反應能力才能實現,尤其這種能力偏向于下意識反應和直覺,很難以體系化的方式教授給更多的人。
說到這里,相信很多人都會想到一個問題,我們能否利用AI的力量復制動作預判能力呢?在AI醫療影像閱片、AI拍照等等技術之中,我們已經可以看到AI對于專家能力的捕捉和復制。
其實此前有不少研究者對此進行相關嘗試,常見的方法是通過Kinect設備來定點采集人的動作,將動作轉化為數據,通過機器學習方法訓練模型,通過預測數據進而模擬人的下一步動作。可很快人們就發現,這種設備采集式的動作預測并沒有什么作用,因為配搭采集設備會極大的阻礙人類進行動作,從數據采集成本上來說也相對較高。
一直以來,科學家們也都在嘗試利用其它方法來實現AI動作預測。
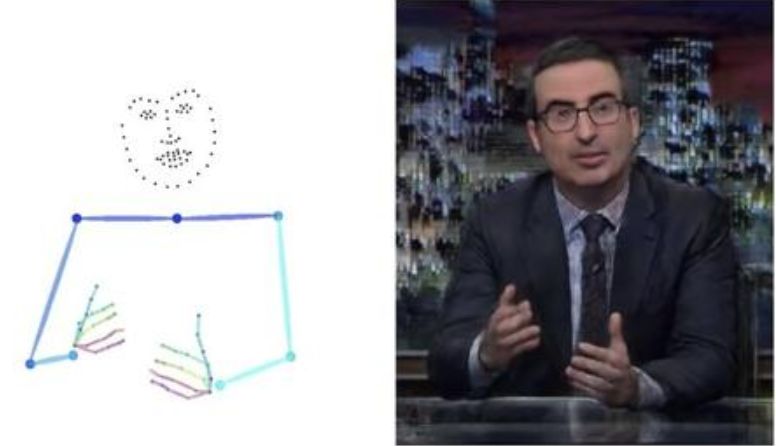 例如通過說話聲音來實現
例如通過說話聲音來實現
在與他人交談,尤其是公開演講時,人們常常會配上手勢來豐富表達。那么有沒有可能,這些手勢動作進行預測呢?在UC Berkeley和MIT的研究中,就通過聲音語言來實現了這一點。
研究人員收集了10個人144小時的演講視頻,一方面通過視頻智能分析算法識別出圖像中演講者手指和手臂的動作,另一方面通過跨模態轉換技術,將演講者的語言聲波變換與動作變換一一對應在一起。如此以來,AI就可以通過聲音來對人類的動作進行下一步預測。
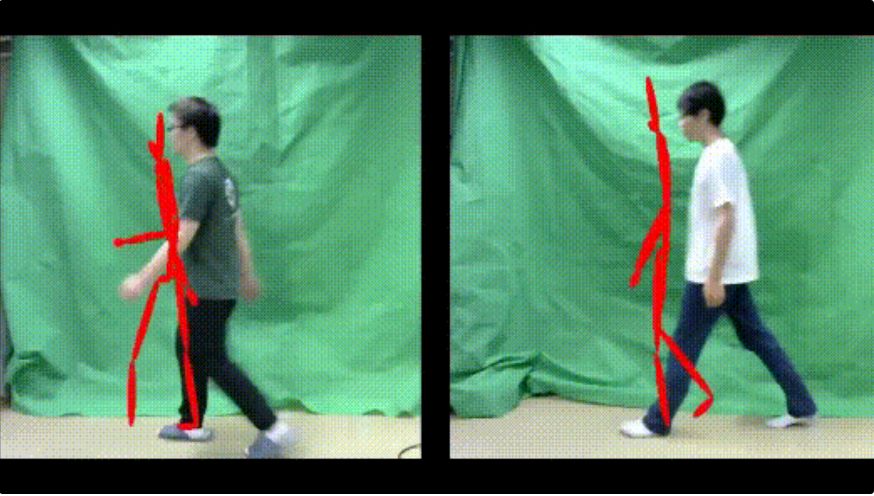 或是通過RGB圖像來預測人體細節姿勢
或是通過RGB圖像來預測人體細節姿勢
在發現了硬件動作采集的不靠譜之后,人們慢慢開始嘗試使用其他方法,例如東京工業大學今年在IEEE上發布了一篇論文,就實現了在簡單背景下(例如比較初級的綠幕)通過2D圖像進行動作捕捉和精準預測。
這一方法利用殘差網絡將人體姿勢圖像轉換成一種2D“位置信息”,再通過LSTM學習時序位置,實現對于位置信息的預測。這種方式雖然對于預測對象所處的背景有所要求,但預測能力非常精準,能夠達到預測15幀后,即0.5秒后的動作。
 甚至直接預言未來五分鐘的世界
甚至直接預言未來五分鐘的世界
有人追求細節動作的預測,但德國波恩大學則是以更粗放的方法,追求更長時間的動作預測。以往借助AI實現的動作預測,通常都屬于“單步預測”,例如AI可以預測拍球一個動作,知道球接觸到手時要向下壓,卻沒法預測拍球之后的運球、投籃等等動作。
而在波恩大學的研究中,研究者將RNN和CNN結合在一起,對不同動作打上標簽,既對動作細節進行預測,又對不同標簽出現的序列進行預測。在這種方式之下,AI僅僅通過兩個小時的學習,就能夠在人類制作沙拉時,對剩下80%的動作進行預測。 從“怎么想”到“怎么做”: AI動作預測能解決哪些問題?
伴隨著AI動作預測在技術上越來越完備,這一技術的應用場景也被開發的越來越多。目前來說,我們可以為AI動作預測找到以下幾種用途。
從基礎角度,AI動作預測可以幫助人類更高效的進行體育訓練。
在東京工業大學的案例中,用戶只需戴上VR眼鏡,就能將AI對于人類走路、格斗、搏擊甚至踢球時的動作預測能力,以圖像的形式投射到眼前人身上。這時再進行動作訓練,就可以幫助普通人更加立體化的理解動作運動邏輯。至于在足球這類運動之中,則可以用來進行戰術分析。
 從更深一層看,只有掌握了利用AI預測動作的能力,才能通過動作細節識別視頻的真假。
從更深一層看,只有掌握了利用AI預測動作的能力,才能通過動作細節識別視頻的真假。
我們已經看到過很多案例,通過幾張照片和一段錄音,就能夠偽造出視頻。那么有了AI動作預測,豈不是更可以學習人類的動作習慣,偽造出更加逼真的視頻?實際上只有當我們研發出AI預測動作的技術之后,才能生成對抗性鑒別器,反向對視頻中內容的真假進行鑒定。
最后,只有當AI擁有預測人類動作的能力時,人機協作才會更加高效。
很多時候我們以為AI想要和人類配合的親密無間,需要了解人類的所思所想,實際上想要達到這一點,AI不需要知道人類“怎么想”,只需要知道人類“怎么做”。德國波恩大學提出的設想,就是讓AI能夠在預測人類動作之后,進行相關反應來配合人類。例如通過預測人類拌沙拉的動作,幫助人類拌好一份半成品沙拉。尤其是在老人護理、兒童陪伴等等場景之中,這些對象由于種種限制可能沒法利用語言與機器人進行交互,這時機器人通過動作預測來實現主動服務就變得十分必要。
人類肉體的步步行動無一不受精神支配,通過大腦運作傳遞肌電信號,才能調動肌肉運動肢體。對于人類和AI來說,弄清大腦的運作方式都有些困難,但如果從“半路”攔截,直接掌握肉體行動的邏輯,或許也是個不錯的解決方案。
當然這種能力并不是誰都能擁有,通常都是“高手限定”。只有累積下大量經驗加上強大的反應能力才能實現,尤其這種能力偏向于下意識反應和直覺,很難以體系化的方式教授給更多的人。
說到這里,相信很多人都會想到一個問題,我們能否利用AI的力量復制動作預判能力呢?在AI醫療影像閱片、AI拍照等等技術之中,我們已經可以看到AI對于專家能力的捕捉和復制。
其實此前有不少研究者對此進行相關嘗試,常見的方法是通過Kinect設備來定點采集人的動作,將動作轉化為數據,通過機器學習方法訓練模型,通過預測數據進而模擬人的下一步動作。可很快人們就發現,這種設備采集式的動作預測并沒有什么作用,因為配搭采集設備會極大的阻礙人類進行動作,從數據采集成本上來說也相對較高。
一直以來,科學家們也都在嘗試利用其它方法來實現AI動作預測。
例如通過說話聲音來實現
在與他人交談,尤其是公開演講時,人們常常會配上手勢來豐富表達。那么有沒有可能,這些手勢動作進行預測呢?在UC Berkeley和MIT的研究中,就通過聲音語言來實現了這一點。
研究人員收集了10個人144小時的演講視頻,一方面通過視頻智能分析算法識別出圖像中演講者手指和手臂的動作,另一方面通過跨模態轉換技術,將演講者的語言聲波變換與動作變換一一對應在一起。如此以來,AI就可以通過聲音來對人類的動作進行下一步預測。
或是通過RGB圖像來預測人體細節姿勢
在發現了硬件動作采集的不靠譜之后,人們慢慢開始嘗試使用其他方法,例如東京工業大學今年在IEEE上發布了一篇論文,就實現了在簡單背景下(例如比較初級的綠幕)通過2D圖像進行動作捕捉和精準預測。
這一方法利用殘差網絡將人體姿勢圖像轉換成一種2D“位置信息”,再通過LSTM學習時序位置,實現對于位置信息的預測。這種方式雖然對于預測對象所處的背景有所要求,但預測能力非常精準,能夠達到預測15幀后,即0.5秒后的動作。
甚至直接預言未來五分鐘的世界
有人追求細節動作的預測,但德國波恩大學則是以更粗放的方法,追求更長時間的動作預測。以往借助AI實現的動作預測,通常都屬于“單步預測”,例如AI可以預測拍球一個動作,知道球接觸到手時要向下壓,卻沒法預測拍球之后的運球、投籃等等動作。
而在波恩大學的研究中,研究者將RNN和CNN結合在一起,對不同動作打上標簽,既對動作細節進行預測,又對不同標簽出現的序列進行預測。在這種方式之下,AI僅僅通過兩個小時的學習,就能夠在人類制作沙拉時,對剩下80%的動作進行預測。 從“怎么想”到“怎么做”: AI動作預測能解決哪些問題?
伴隨著AI動作預測在技術上越來越完備,這一技術的應用場景也被開發的越來越多。目前來說,我們可以為AI動作預測找到以下幾種用途。
從基礎角度,AI動作預測可以幫助人類更高效的進行體育訓練。
在東京工業大學的案例中,用戶只需戴上VR眼鏡,就能將AI對于人類走路、格斗、搏擊甚至踢球時的動作預測能力,以圖像的形式投射到眼前人身上。這時再進行動作訓練,就可以幫助普通人更加立體化的理解動作運動邏輯。至于在足球這類運動之中,則可以用來進行戰術分析。
從更深一層看,只有掌握了利用AI預測動作的能力,才能通過動作細節識別視頻的真假。
我們已經看到過很多案例,通過幾張照片和一段錄音,就能夠偽造出視頻。那么有了AI動作預測,豈不是更可以學習人類的動作習慣,偽造出更加逼真的視頻?實際上只有當我們研發出AI預測動作的技術之后,才能生成對抗性鑒別器,反向對視頻中內容的真假進行鑒定。
最后,只有當AI擁有預測人類動作的能力時,人機協作才會更加高效。
很多時候我們以為AI想要和人類配合的親密無間,需要了解人類的所思所想,實際上想要達到這一點,AI不需要知道人類“怎么想”,只需要知道人類“怎么做”。德國波恩大學提出的設想,就是讓AI能夠在預測人類動作之后,進行相關反應來配合人類。例如通過預測人類拌沙拉的動作,幫助人類拌好一份半成品沙拉。尤其是在老人護理、兒童陪伴等等場景之中,這些對象由于種種限制可能沒法利用語言與機器人進行交互,這時機器人通過動作預測來實現主動服務就變得十分必要。
人類肉體的步步行動無一不受精神支配,通過大腦運作傳遞肌電信號,才能調動肌肉運動肢體。對于人類和AI來說,弄清大腦的運作方式都有些困難,但如果從“半路”攔截,直接掌握肉體行動的邏輯,或許也是個不錯的解決方案。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
