DeepSeek代碼開源第一彈Flash MLA,揭秘大模型訓練低成本關鍵快訊
通過KV壓縮、低秩降維等技術實現高效長序列處理與資源優化,顯著減少了大模型訓練和推理過程中的內存占用 今天開源的MLA是DeepSeek在注意力機制上的重要創新,今天DeepSeek開源首個代碼庫Flash MLA。
【TechWeb】2月24日消息,隨著DeepSeek大模型開源引發全球熱潮后,2月21日DeepSeek在社交平臺X發文稱,這周起會陸續開源5個代碼庫。
今天DeepSeek開源首個代碼庫Flash MLA,引發極大關注,截至目前github Star星數已經超過4.5k。

Flash MLA是DeepSeek針對英偉達Hopper GPU優化的高效MLA解碼內核,其特別針對可變長度序列作了優化,現已投入生產。
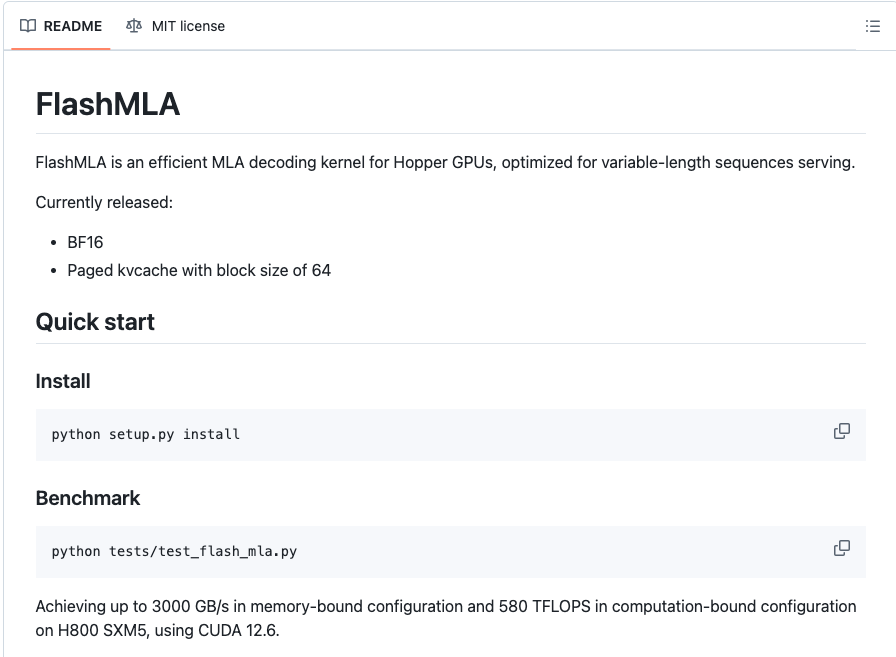
FlashMLA的使用基準為:Hopper GPU、CUDA 12.3及以上版本、PyTorch 2.0及以上版本。
經實測,FlashMLA在H800 SXM5平臺上(CUDA 12.6),在內存受限配置下可達最高3000GB/s,在計算受限配置下可達峰值580 TFLOPS。
這種優化可以確保FlashMLA在高性能硬件上有效地處理大語言模型和其他AI應用程序的密集計算需求。
目前已經發布的內容包括:采用BF16,塊大小為64的分頁kvcache(鍵值緩存)。
團隊在致謝部分表示,FlashMLA的設計參考了FlashAttention 2&3以及CUTLASS的技術實現。

資料顯示,FlashAttention 是一種針對Transformer模型注意力計算的高效優化算法,由斯坦福團隊于2022年提出,核心目標是通過硬件感知的內存管理和計算流程重構,顯著降低長序列處理時的顯存占用與計算延遲。
CUTLASS(CUDA Templates for Linear Algebra Subroutines)是NVIDIA推出的開源高性能計算庫,專為GPU加速的線性代數計算(尤其是矩陣乘法和卷積)設計。其核心目標是通過模塊化模板和硬件級優化,為開發者提供靈活、高效的底層計算內核,支撐AI訓練、科學計算與圖形渲染等領域。
根據DeepSeek過往提交的論文,DeepSeek大模型訓練成本大幅下降有兩項關鍵技術,一是MoE,另一個就是今天開源的MLA(多頭潛注意力)。
DeepSeek的成本涉及兩項關鍵的技術:一個是MoE,一個就是MLA(Multi-head Latent Attention,多頭潛注意力)。
MLA旨在優化傳統Transformer架構的效率與性能,其核心原理包括:
KV壓縮與潛在變量:將鍵(Key)和值(Value)聯合壓縮為低維潛在向量,顯著減少推理時的KV緩存,降低內存占用。計算時通過升維恢復原始信息,平衡壓縮效率與計算精度。
低秩降維技術:對查詢(Queries)進行低秩壓縮(降維后再升維),減少訓練中的激活內存(activation memory),但需注意此操作不影響KV緩存。
動態序列處理:針對可變長度輸入序列優化,支持高效處理不同長度的句子(如長文本對話場景)。
MLA可將每個查詢KV緩存量減少93.3%,顯著減少了大模型訓練和推理過程中的內存占用
今天開源的MLA是DeepSeek在注意力機制上的重要創新,通過KV壓縮、低秩降維等技術實現高效長序列處理與資源優化,成為其模型性能領先的關鍵技術之一。
本周后續,DeepSeek還將陸續開源4個代碼庫,期待一下!(宜月)
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
