最高日賺346萬元!DeepSeek商業模式受質疑,官方回應快訊
潞晨科技暫停DeepSeek API服務 就在DeepSeek披露大規模部署成本和收益之后,暫停DeepSeek API服務,DeepSeek官方發布《DeepSeek-V3/R1推理系統概覽》技術文章。
【TechWeb】3月1日,DeepSeek在開源周最后一天拋出壓軸成果——V3/R1推理系統理論日利潤高達47.5萬美元(約合346萬元人民幣)。這一驚人數字引發人們對于AI模型商業化的討論。
最高日賺346萬元
昨日,DeepSeek官方發布《DeepSeek-V3/R1推理系統概覽》技術文章,首次公布模型推理系統優化細節,并披露成本利潤率關鍵信息。
DeepSeek統計了2月27日24點到2月28日24點,最近的24小時里DeepSeek V3 和 R1推理服務占用節點總和,峰值占用為278個節點,平均占用226.75個節點(每個節點為8個H800 GPU)。假定GPU租賃成本為2美元/小時,DeepSeek每日總成本為8.7萬美元(折合人民幣約63萬元)。
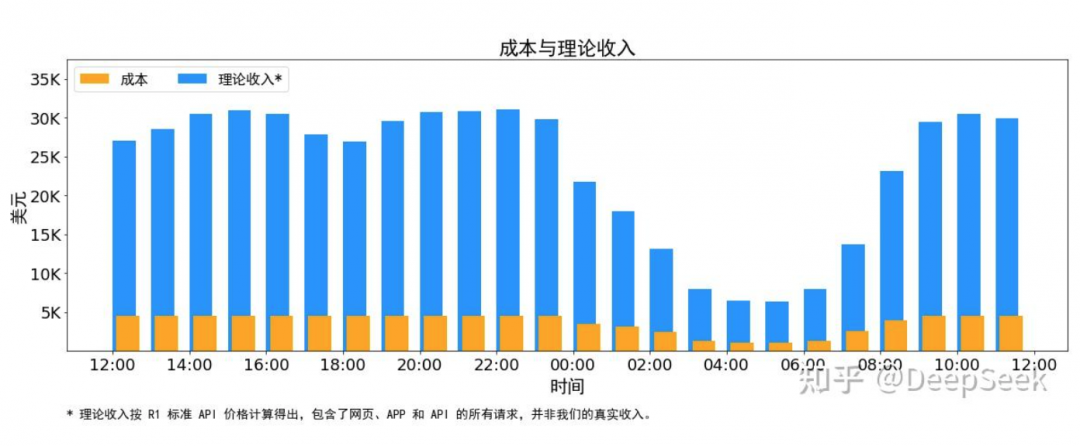
如果所有tokens全部按照DeepSeek R1的定價計算,理論上一天的總收入為56.2萬美元(折合人民幣約409萬元),成本利潤率高達545%。這意味著,理論上,DeepSeek每日凈賺47.5萬美元,約合人民幣346萬元。
商業模式受質疑,潞晨科技暫停DeepSeek API服務
就在DeepSeek披露大規模部署成本和收益之后,潞晨科技突然宣布:暫停DeepSeek API服務。

潞晨科技官方公眾號發文稱,“潞晨云將在一周后停止提供DeepSeek API服務,請盡快用完您的余額。如果沒用完,我們全額退款。”
公開資料顯示,潞晨科技是一家致力于“解放AI生產力”的全球性企業,核心產品包括大模型訓練推理系統Colossal-AI和視頻大模型Open-Sora,此前業務也涉及賣DeepSeek API。
2月4日,潞晨科技宣布攜手華為昇騰,聯合發布基于昇騰算力的DeepSeek-R1系列推理API,及云鏡像服務。
但在2月9日,潞晨科技CEO尤洋發文指出,“MaaS (Model as a Service)在中國短時間內可能是最差的商業模式。阿里云/百度云/騰訊云等相互內卷低價和免費,滿血版的DeepSeek R1每百萬token官方也只能收到16元……如果滿血版的DeepSeek R1每日輸出1000億token,那么每月的機器成本是4.5億,虧損4億!用戶越多,虧損越多。”

在DeepSeek首次公開披露自己的成本利潤率等關鍵信息之后,尤洋發文提到,DeepSeek這篇文章中的數據對計算MaaS成本沒有任何參考價值。文章中把DeepSeek網頁、APP和MaaS API的token數加在一起計算,意味著對成本的攤薄。
尤洋表示,DeepSeek的MaaS要想有一個這么高滿負荷的狀態,必須要讓自己的APP和網頁始終超負荷運轉。MaaS是ToB的,是服務APP,最大的問題是機器利用率的不確定性以及自己沒有模型壁壘而承受的低毛利負毛利價格戰。
據第一財經報道,尤洋認為,OpenAI收高額月費才是唯一可持續的商業模式。目前,DeepSeek采用開源免費+分層B端收費模式,通過開放核心技術吸引開發者共建生態,核心盈利來源于企業定制化服務以及母公司的資金支持,而OpenAI基本堅持閉源+訂閱制分層收費,通過ChatGPT Plus等訂閱服務(200美元/月)和API調用收費實現盈利,開源了一些早期模型比如GPT2。
日前,OpenAI發布GPT-4.5大模型,API價格為每百萬Tokens 75美元,相比DeepSeek的正常價格,GPT-4.5輸入價格達到280倍。如果以DeepSeek前幾天發布的API淡季折扣價計算,GPT-4.5輸入價格(緩存命中)是其1000多倍。
DeepSeek回應
對于盈利問題,DeepSeek其實多次說過自家的API不賠本。
去年5月,時任DeepSeek員工的羅福莉在知乎透露,“大家不用擔心模型斷更,也不用擔心API漲價(目前就是大規模服務的價格,不虧本,利潤率超50%)。
DeepSeek CEO梁文鋒也曾在接受媒體采訪時表示,“我們只是按照自己的步調來做事,然后核算成本定價。我們的原則是不貼錢,也不賺取暴利。這個價格也是在成本之上稍微有點利潤。”
在最新的《DeepSeek-V3/R1推理系統概覽》文章中,DeepSeek披露理論上一天的總收入為56.2萬美元,成本利潤率高達545%。“當然實際上沒有這么多收入,因為 V3 的定價更低,同時收費服務只占了一部分,另外夜間還會有折扣。”
而DeepSeek能做到這一利潤率,部分原因是團隊將優化做到極致,實現了對GPU的最大限度使用。DeepSeek在文章一開頭就寫道:“DeepSeek-V3 / R1推理系統的優化目標是:更大的吞吐,更低的延遲。”

為此DeepSeek的方案是使用大規模跨節點專家并行(Expert Parallelism /EP),EP提高了GPU矩陣乘法的效率,提高吞吐。此外,EP使得專家分散在不同的GPU上,每個GPU只需要計算很少的專家(因此更少的訪存需求),從而降低延遲。
硅基流動創始人袁進輝對此評論稱,“DeepSeek 官方披露大規模部署成本和收益,又一次顛覆了很多人認知。現在很多供應商做不到這個水平,主要是V3/R1架構和其它主流模型差別太大了,由大量小Expert(專家)組成,導致瞄準其它主流模型結構開發的系統都不再有效,必須按照DeepSeek報告描述的方法才能達到最好的效率,而開發這樣的系統難度很高,需要時間,幸好這周DeepSeek五連發已經把主要模塊開源出來了,降低了社區復現的難度。”
最新消息顯示,今日早間,尤洋刪除了其質疑DeepSeek的相關內容,并在微博和知乎上發文道歉,稱“本人昨天情緒太沖動,說了一些讓人誤解deepseek infrastructure團隊的話。deepseek infrastructure團隊技術一流并給開源社區做出巨大貢獻。本人誠摯道歉,已經刪除不當表述,感謝大家提醒!”

1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
